A Tiny Crew of Agents Running My Homelab
One main agent, two specialists, Gemma 4 E4B doing the thinking. Pi holding it all together.
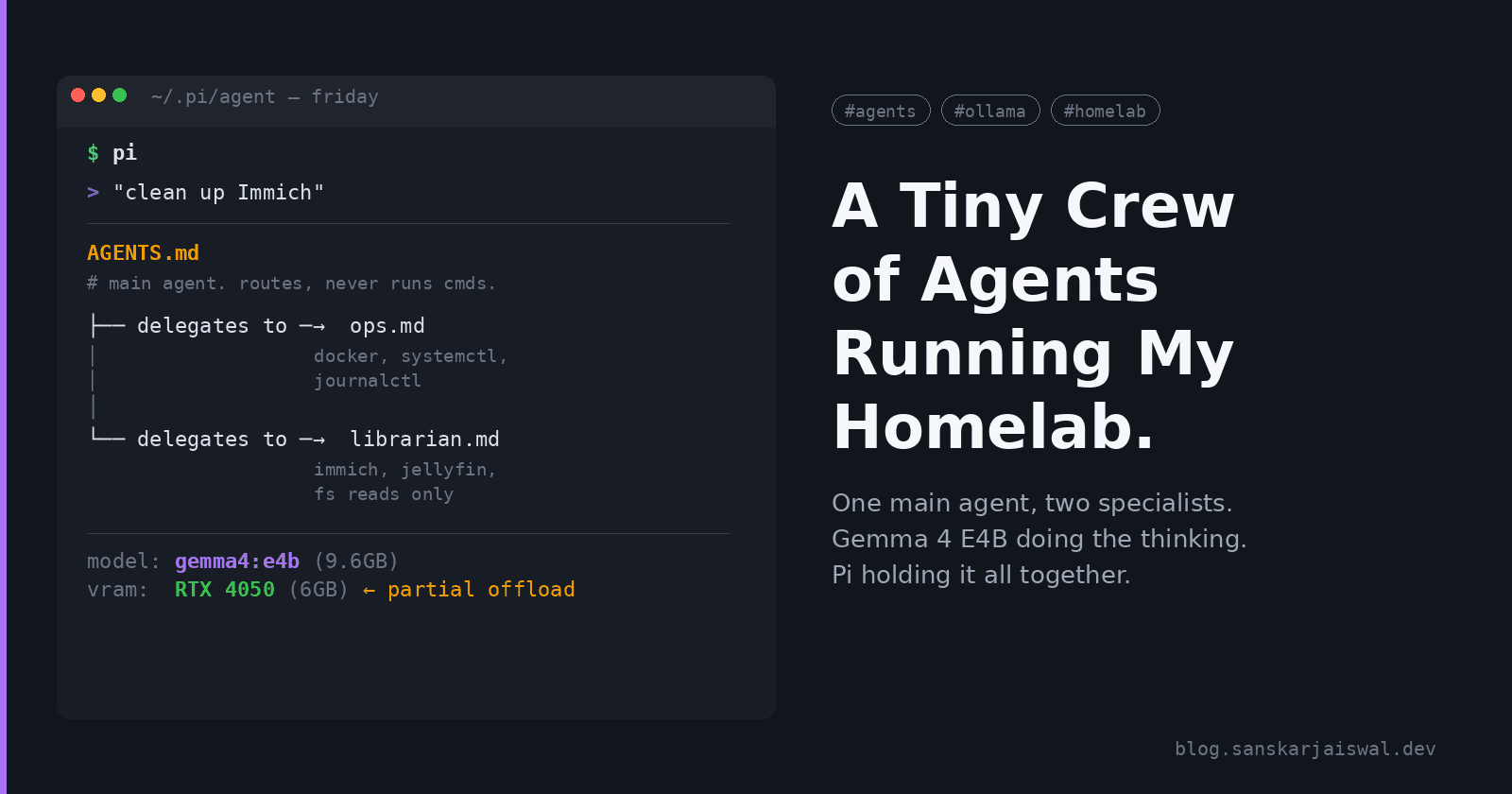
The first version of this setup was one agent that did everything, and the thing that finally broke me was a Saturday evening where I asked it to "clean up Immich" and it instead restarted the Jellyfin container because both contain the word "photo" somewhere in their config. Nothing important lost. But I was sitting there watching Jellyfin reindex a ~600GB library for no reason, and that was the moment.
What I actually wanted was a crew. One main agent that delegates, two specialists with narrow jobs, each in its own process so they can't step on each other. Pi with a sub-agent extension gets me there, running Gemma 4 E4B locally on the 4050 laptop. No cloud calls, no rate limits, no rationing.
This is how I set it up and where the VRAM bites.
Why Pi
I've been using Pi (Mario Zechner's terminal coding agent) for a while. It's minimal by design. No MCP, no plan mode, no built-in sub-agents, no permission popups. Extensions are the composition unit, which sounded annoying on paper but in practice means I'm not fighting someone else's idea of how an agent should work.
One thing to flag up front: Pi runs in full YOLO mode by default. Unrestricted filesystem access, no pre-checks, it'll run whatever the model decides. That's fine for a coding harness where you want speed. For a homelab operator, guardrails are your job. I'll come back to this.
For sub-agents specifically, Mario himself is skeptical. His preferred pattern is a slash command that spawns a fresh pi --print via bash for one-off things like code review. I went with a sub-agent extension instead because I wanted named specialists with their own system prompts and tool scopes, not just "spawn yourself with this prompt." I'm not 100% sure that was the right call and I'll probably re-run this whole thing with the slash-command pattern in a month to compare.
The one I'm using is mjakl/pi-subagent. Agents are defined as Markdown files with YAML frontmatter. Each subagent runs in a separate pi process with no shared state, which is exactly what I want.
| Role | Scope | What it touches |
|---|---|---|
| Main agent | Routes requests, summarises outcomes | Nothing directly, it delegates |
| Ops | Container health, restarts, logs | docker, systemctl, journalctl |
| Librarian | Immich/Jellyfin housekeeping | Immich CLI, Jellyfin API, filesystem reads |
I deliberately did not add a third specialist. Every extra role is another system prompt to maintain and another place where the wrong agent can touch the wrong thing.
The model: Gemma 4 E4B on a 4050 6GB
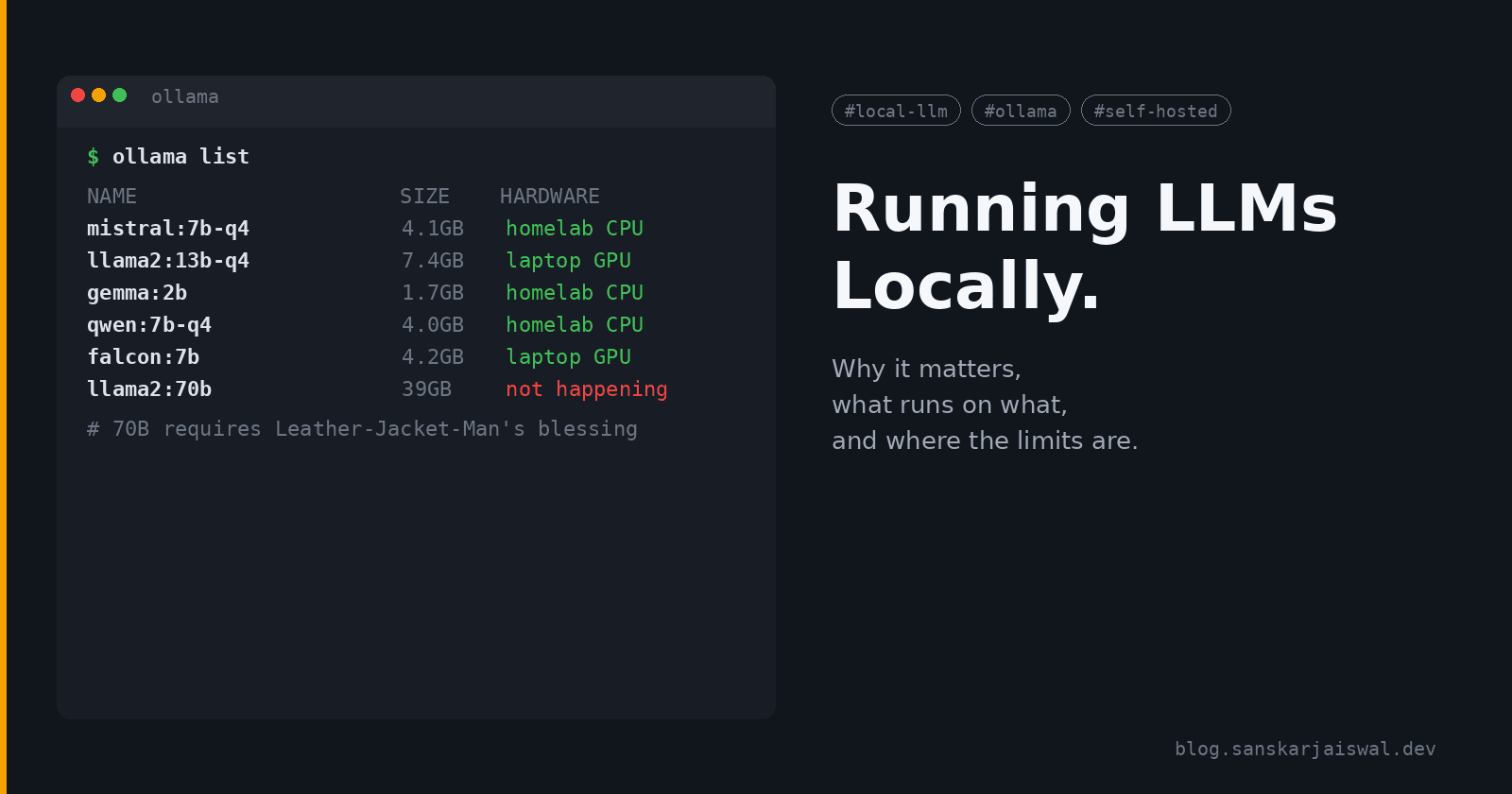
Gemma 4 dropped a couple of weeks ago. E4B is the edge model: 4.5B effective parameters (8B with embeddings), native function calling, 128K context, multimodal. The Q4_K_M GGUF on Ollama is 9.6GB.
Yes, 9.6GB. The 4050 has 6GB of VRAM.
Ollama handles this by partially offloading layers to system RAM. It works, it's just slower than the breathless "E4B fits on any 6GB card" takes you'll read. What actually fits on 6GB is the inference footprint at small context, not the full model. Weights stream in from the 16GB of system RAM as needed, GPU utilisation looks spiky, and tokens/sec is maybe 60-70% of what you'd see on a fully-resident 8GB card. The single piece of advice I'd give anyone considering the same setup is don't expect a free ride. It's usable. I would not spec this for production.
ollama pull gemma4:e4b
ollama run gemma4:e4b "hello"
The setup
Install Pi
npm install -g @mariozechner/pi-coding-agent
Add Ollama as a provider
Edit ~/.pi/agent/models.json:
{
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434/v1",
"api": "openai-completions",
"apiKey": "ollama",
"compat": {
"supportsDeveloperRole": false,
"supportsReasoningEffort": false
},
"models": [
{
"id": "gemma4:e4b",
"name": "Gemma 4 E4B (Local)",
"reasoning": true,
"contextWindow": 16000,
"maxTokens": 4000
}
]
}
}
}
A few non-obvious bits. The apiKey field is required but Ollama ignores it so any value works. The two compat flags are there because Ollama's OpenAI-compatibility layer doesn't understand the developer role or reasoning_effort parameter. Without those flags Pi will silently send requests Ollama can't parse and you'll spend an afternoon wondering why your local model is suddenly mute.
I cap contextWindow at 16K. E4B advertises 128K but on 6GB the KV cache grows linearly and a 128K cache will eat system RAM alive before you've even said hello. 16K is plenty for a homelab operator doing single tasks, and if I ever need more I can just bump it for that session.
Then in ~/.pi/agent/settings.json:
{
"defaultProvider": "ollama",
"defaultModel": "gemma4:e4b"
}
Install the sub-agent extension
mkdir -p ~/.pi/agent/extensions
cd ~/.pi/agent/extensions
git clone https://github.com/mjakl/pi-subagent.git
cd pi-subagent
npm install
Define the specialists
pi-subagent expects agent files with YAML frontmatter. I put them in ~/.pi/agent/ alongside the main AGENTS.md:
~/.pi/agent/
├── AGENTS.md # main agent: who does what
├── ops.md # ops specialist
└── librarian.md # librarian specialist
Main agent (AGENTS.md) — short, strict:
You are the main agent for a homelab crew on host friday.
You do NOT run commands directly. You delegate to specialists:
- ops: container health, restarts, logs, systemd, reachability checks
- librarian: Immich and Jellyfin housekeeping, dedup, library scans
For every request:
1. Decide which specialist owns it. If unclear, ask one question.
2. Delegate with a single, scoped instruction. Use fully-qualified service names.
3. Summarise the specialist's receipt back to me in <= 3 lines.
4. Never combine specialists in one turn. One task, one specialist.
If a request is not ops or librarian, say so. Do not improvise.
Ops (ops.md) — narrow tools, receipt mandatory:
---
name: ops
description: Container health, restarts, logs, systemd diagnostics on friday
tools: read,bash
mode: spawn
---
You manage containers and services on friday.
Allowed: docker ps, docker logs, docker restart, systemctl status,
journalctl, curl (localhost only).
NOT allowed: docker rm, docker volume rm, docker system prune, anything
destructive. If a task requires destruction, refuse and explain.
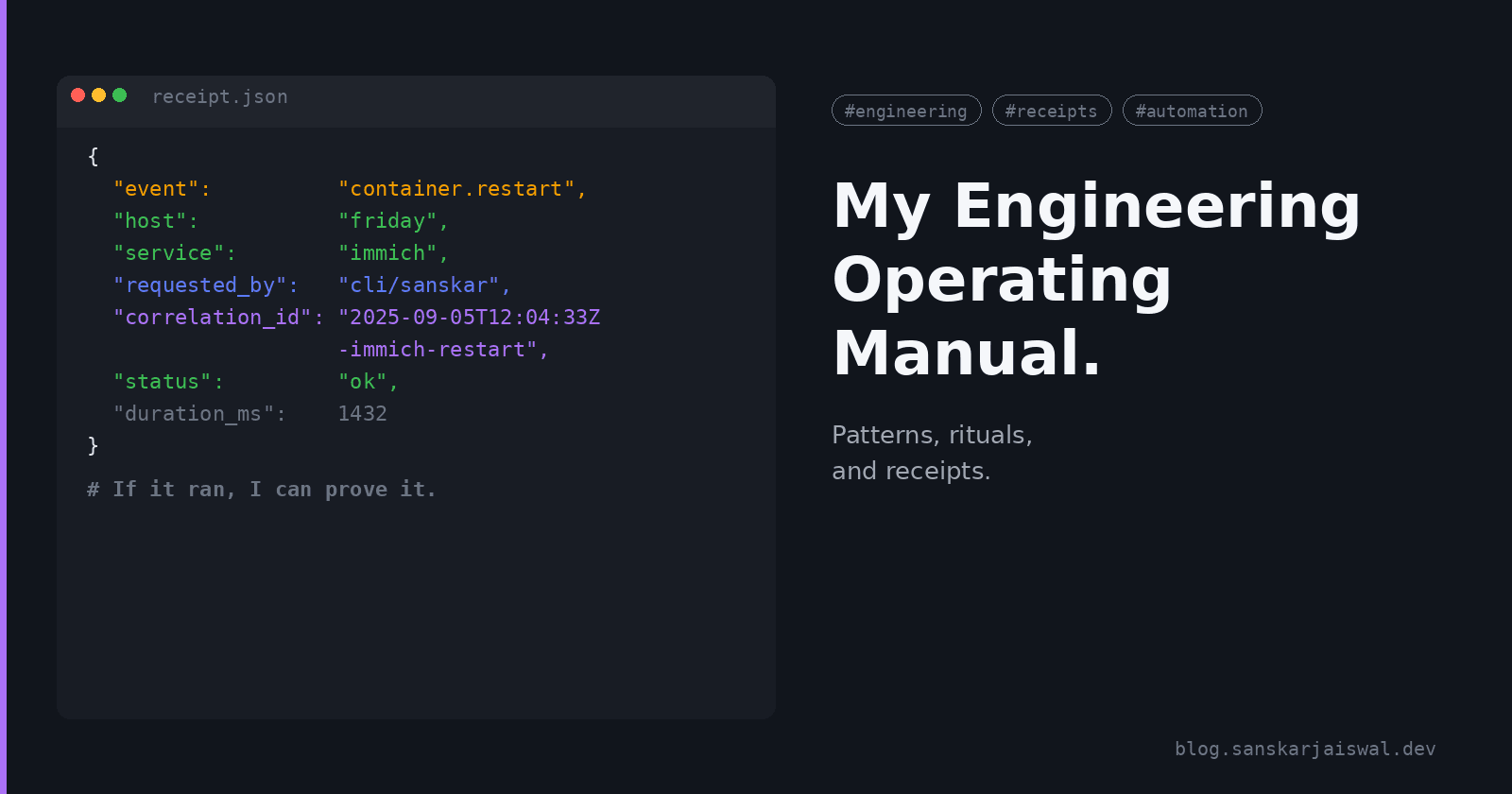
After every action, emit a receipt JSON:
{
"event": "<event.name>",
"host": "friday",
"service": "<service>",
"requested_by": "main",
"correlation_id": "<ISO-timestamp>-<service>-<action>",
"status": "ok|error",
"duration_ms": <int>
}
If you cannot emit the receipt, the action did not happen.
Librarian (librarian.md):
---
name: librarian
description: Immich and Jellyfin housekeeping, dedup scans, library refresh
tools: read,bash
mode: spawn
---
You manage media libraries on friday.
Allowed: Immich CLI (read + dedup-dry-run), Jellyfin API (scan, library
refresh), filesystem reads under /srv/media.
NOT allowed: deleting files, writing outside /tmp, touching originals.
Any "clean up" is dry-run by default. Actual deletes require an explicit
confirmed: true field in the task.
Emit the same receipt JSON as Ops. Include a dry_run: true|false field.
The tools: read,bash is deliberate. No write, no edit. They can read state and run commands but they can't modify files directly, and for ops work that's enough.
Thinking mode
Gemma 4's thinking is toggled by a <|think|> token at the start of the system prompt. Add it where you want reasoning, leave it out where you want speed.
I landed on: thinking on for the main agent (it's doing routing, worth the latency), off for Ops ("restart immich" shouldn't require a philosophical detour), on for Librarian (deciding what's a dedup candidate needs actual reasoning).
What a real turn looks like
Me, at the Pi prompt:
immich is slow and the homepage is half-loaded
Main agent routes it to Ops. Ops runs docker ps | grep immich, sees immich-server is in a restart loop, tails the last 200 log lines, spots a Postgres connection timeout, restarts immich-server, waits 5s, curls the healthcheck, emits:
{
"event": "container.restart",
"host": "friday",
"service": "immich-server",
"requested_by": "main",
"correlation_id": "2026-04-17T09:22:11Z-immich-server-restart",
"status": "ok",
"duration_ms": 5840
}
Main agent replies:
Ops restarted immich-server after a DB timeout. Health check green. Receipt 2026-04-17T09:22:11Z-immich-server-restart.
That correlation_id shows up in the Discord notification, in the container log, and if I need it, in Grafana. No arguments later about what happened when.
Gotchas that cost me time
The model is bigger than the VRAM
I didn't believe this until the first long session. E4B Q4_K_M is 9.6GB, the 4050 is 6GB, offload happens, sustained throughput suffers. If you're spec'ing a dedicated crew machine, a 4060 Ti 8GB or 4070 is a much happier place than what I'm running on.
Thinking-off Ops is confidently wrong on ambiguous input
This is the one that cost me the Jellyfin reindex I mentioned at the top. "Restart the photo thing" is a perfectly reasonable thing to type at 10pm on a Saturday and thinking-off Ops will parse it, pick the first container whose metadata mentions photos, and go. The model isn't dumb, it's just fast and decisive about the wrong thing.
Fix is structural: make the main agent do the disambiguating (it's thinking-on), and require it to hand Ops a fully-qualified service name. Line 2 of the main agent's AGENTS.md is that rule. I added it after the Jellyfin incident, not before.
Sub-agents don't share memory
My first instinct was to let Ops see what Librarian just did. Fought this for an evening before I realised the whole point of spawn mode is isolated context, and what I actually wanted was for the receipts to be the shared memory. Main agent reads both receipts, correlates them by timestamp, done. No cross-specialist context bleed, no growing context window, no confusion about whose turn it is.
pi-subagent does have a fork mode that inherits parent context. It's tempting for follow-up tasks. I'm staying on spawn because the cost in tokens and the risk of leaking unrelated context into a specialist's head both feel worse than the inconvenience of one extra turn.
Pi is YOLO and your prompts are not a security boundary
Allow-lists in a system prompt are a style guide the model mostly follows. On a good day. If your Ops agent decides docker system prune is a clever shortcut, nothing in Pi will stop it.
What actually works:
Run Pi in a container or VM with scoped mounts and a non-root user
Use path-protection or permission-gate extension examples for belt-and-braces
Keep
toolsin the subagent frontmatter as narrow as possible,read,bashis the smallest useful set
I run mine in a podman container with /srv/media mounted read-only for Librarian and a docker socket proxy (tecnativa/docker-socket-proxy) for Ops so it can list and restart containers but can't do rm or prune even if it wanted to. Took a weekend to get right. I was also paranoid enough that I initially didn't give Librarian any bash at all, and then realised it needed bash to call the Immich CLI, and re-added it with a narrower allow-list in the prompt.
The Librarian wanted to delete things on its first test run
I typed "clean up duplicate photos" as a throwaway test. Librarian dry-ran (thanks to the prompt rule), reported around 847 dedup candidates, touched nothing. Good agent. If I had skipped the dry-run-by-default rule in its prompt I would be restoring from backup right now, and backups are fiction until you've tested them, which mercifully I had [after a hard disk event last year that I still haven't written about].
My setup in tl;dr
Laptop: i5 12th gen, RTX 4050 6GB VRAM, 16GB system RAM
Runtime: Ollama serving
gemma4:e4b(Q4_K_M, 9.6GB, partial GPU offload)Agent harness: Pi + mjakl/pi-subagent
Crew: Main + Ops + Librarian (all spawn mode)
Thinking: on for Main/Librarian, off for Ops
Context cap: 16K per agent
Tools per specialist:
read,bashonlyIsolation: podman container, scoped mounts, docker-socket-proxy for Ops
Receipts: JSON to stdout, tailed to a log file, Discord webhook for failures, eventually into Grafana
What I want to try next
Route Ops to
fridayvia SSH and keep the agent runtime on the laptop. The SSH extension example in pi-mono looks straightforward. No reason the crew needs to live on the machine it manages.Do the whole thing again with Mario's slash-command pattern instead of a sub-agent extension. Same prompts, same roles,
pi --printspawns. Measure tokens, latency, and whether it feels different. I might have over-engineered this.A Scribe specialist for weekly homelab digests. "What changed on friday this week" → markdown file, committed to my notes repo. Not critical, would be nice.
Dynamic thinking toggle: Ops flips to thinking-on automatically when the input contains any error signature it hasn't seen before. Right now I do this manually with
/model.26B A4B on the OptiPlex someday: Long shot ... that box is CPU-only and I think the Jensen Huang tax for more VRAM is still not in budget, maybe a mac mini soon o.0
Closing thoughts
The thing I keep learning with local LLMs is that the model isn't the hard part anymore. Gemma 4 E4B is honestly great at function calling, even when it's half-swapped to system RAM. The hard part is the scaffolding. Who's allowed to do what, how actions leave a trail, what's reversible.
Pi gets out of the way on exactly the right axis. Three Markdown files and a docker-socket-proxy, and I have a homelab operator that can restart a service, check on my photo library, and leave a receipt for every action. None of it is flashy. The VRAM ceiling is real and I'll want more of it before the year is out.
But it's mine. And that's the point.