Running LLMs Locally: Why It's Important and How to Do It
Exploring Local LLM Projects, Trade-Offs, and Insights
Why I Started Looking Beyond Cloud APIs
Most of my first experiences with LLMs were through OpenAI’s API and Azure OpenAI Service at work.
They’re honestly great when you’re just starting out. You hit an endpoint, you get GPT-4 level answers, and life feels good. No GPU drivers, no CUDA errors, no headaches.
But after a while I started hitting the usual walls:
The bill at the end of the month started looking like my rent. [exaggerated ;)]
I had no real control over what was happening under the hood.
Privacy was always in the back of my mind. Some data just doesn’t feel right sending off to the cloud.
And of course, you’re completely at the mercy of whatever models and limits the provider decides.
So I thought… why not run some of this stuff myself? Worst case I burn some hours fighting Docker. Best case I end up with my own AI assistant that doesn’t need an internet connection to work.
What’s Possible These Days
Running your own models used to be something only labs with racks of GPUs could do. Now it’s surprisingly doable at home.
Models worth trying
Mistral: small, fast, scary good at reasoning for its size.
LLaMA 2: the “default” open model. Huge community, easy to fine tune.
Falcon: solid multilingual capabilities.
Gemma and StableLM: lighter models that don’t need monster GPUs.
Tools that make life easier
Ollama: probably the smoothest way to run models locally.
Text Generation Inference (TGI): if you want a proper serving stack.
LangChain and LangGraph: orchestration so your models can actually do more than parrot back text.
Model Context Protocol (MCP): lets LLMs hook into tools and data. I use this with my homelab assistant.
Hardware reality check
Mid-size models like 7B to 13B will happily run on a decent GPU with 12 to 16 GB of VRAM.
If you don’t have that, quantized models can limp along on CPU with enough RAM.
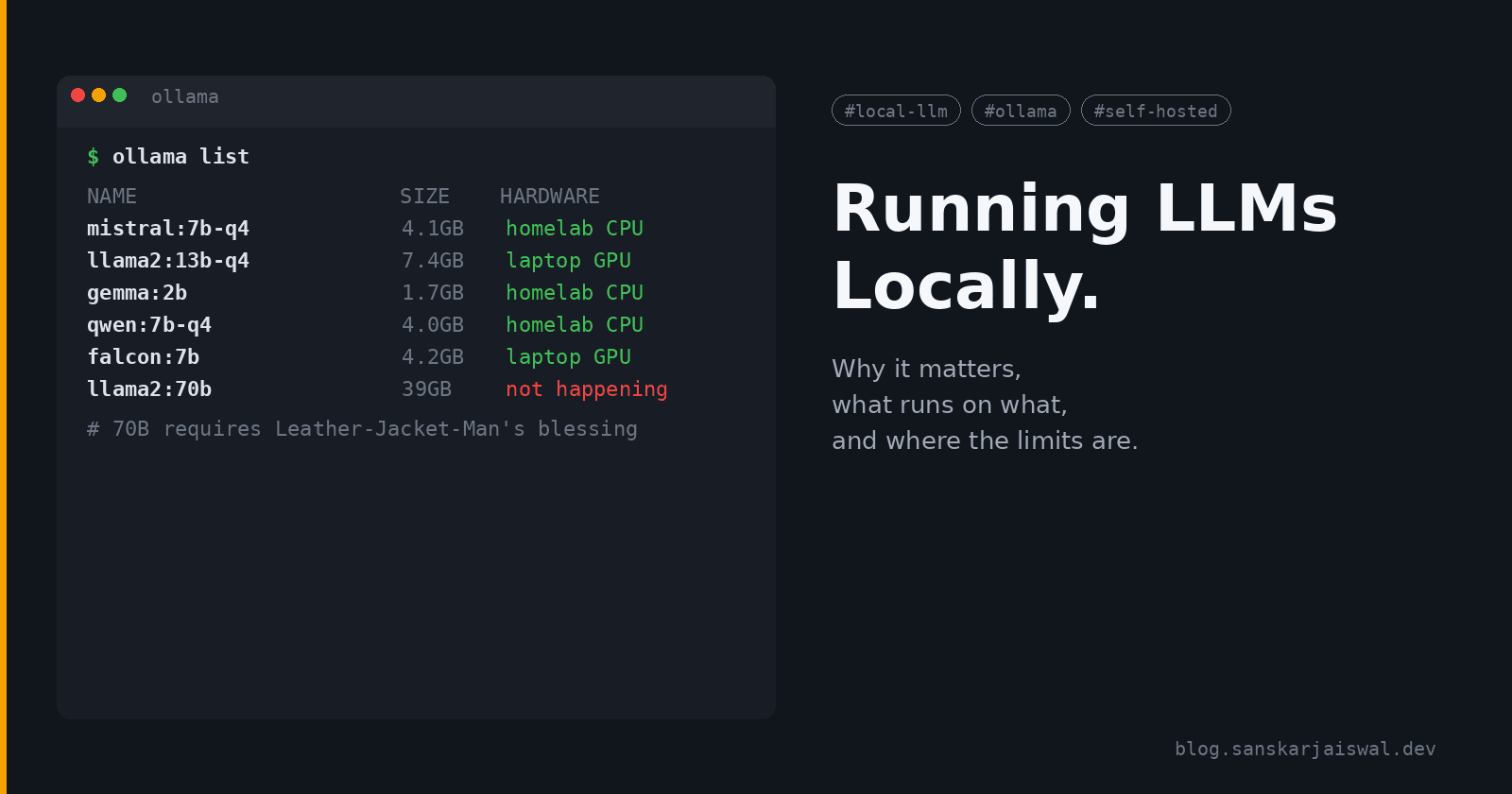
The giant 70B models are still a no go unless you own a data center or happen to be best friends with Leather-Jacket-Man (Jensen Huang).
My Setup in tl;dr
Homelab: OptiPlex i3-7100T, CPU only, quantized models. Runs the always-on stuff: Jarvis-style control, finance RAG, FastMCP monitors that ping me on Discord.
Laptop: i5 12th gen + RTX 4050 6 GB. Handles heavier chat and image work with Stability Matrix + ComfyUI, and LM Studio for local chat.
Homelab = reliable background. Laptop = GPU playground.
Cloud vs Local: The Reality Check
| Thing | Cloud APIs (OpenAI / Azure) | Self Hosted LLMs |
|---|---|---|
| Setup | Call an API and you’re done | Get ready to fight drivers and config files |
| Models | GPT-4, GPT-4o, all the shiny toys | Mostly open source like Mistral or LLaMA |
| Latency | Pretty low but internet dependent | Can be higher especially on CPU only |
| Cost | Pay per token, sometimes feels like highway robbery | One time hardware cost, then just power bills |
| Privacy | Data leaves your network | Data never leaves your machine |
| Control | You tweak a few parameters at best | Full control: quantization, caching, fine tuning |
| Scaling | Basically infinite | Limited to what’s inside your case |
Lessons I’ve Learned
Don’t try to run the biggest model first. Start with a 2B or 7B model and see what happens.
Quantization is your friend. It’s basically magic for smaller hardware.
The real power comes when you connect models to things. Scripts, dashboards, automations… that’s where it feels useful.
Expect things to break. You’ll see hallucinations, weird limits, maybe even kernel panics if you get lucky.
The open source scene moves ridiculously fast. A year ago Mistral didn’t even exist, now it’s everywhere.
What I Want to Try Next
Multimodal models that can handle both text and images.
A hybrid setup where I keep local models for everyday use but call the cloud for really heavy lifting.
Fine tuning on my own data so my assistant understands my configs and logs without me explaining every time.
Adding a proper GPU node in the homelab so I don’t have to lean on my laptop as much. [long shot.. I’ll be spending that money elsewhere]
How to Get a Local LLM Running in 10 Minutes
You have two easy paths. Pick your vibe.
Option A: Click-and-go with LM Studio
Install LM Studio. Grab the installer for your OS from the official site.
Download a model. Open LM Studio and use the Discover tab to fetch something like Mistral 7B, Qwen, or Gemma.
Chat. Hit New Chat, pick the model, and talk to your computer like it owes you answers.
Why this path? Zero terminal work, fast feedback, built-in model browser. Great for laptops and first-timers.
Option B: Terminal-friendly with Ollama
Install Ollama. The easiest way is their one-liner:
curl -fsSL https://ollama.com/install.sh | sh
On Fedora you can even:
sudo dnf install ollama
Pull and run a model. For a solid starter:
ollama run mistral
The first run downloads the weights, then drops you in an interactive prompt.
Use it from apps. Many local tools can point to the Ollama endpoint. If you know LangChain or LlamaIndex, you can wire it up in a few lines.
Why this path? Scriptable, container-friendly, and good for homelabs.
Bonus: Image generation with Stability Matrix + ComfyUI
If you want images too:
ComfyUI core. Install by cloning the repo and installing dependencies, then run
pythonmain.py.Quality-of-life. Add ComfyUI-Manager to install and manage custom nodes from inside ComfyUI.
Use Stability Matrix as the front end and manager. It streamlines ComfyUI setup and running workflows so you spend less time chasing missing nodes and more time making cool images.
Tiny gotchas that save hours
If a model won’t load, try a smaller one or a more aggressive quantized build.
Keep an eye on VRAM usage. 7B is comfy on 8 to 12 GB, 13B prefers 12 to 16 GB. If you’re on CPU, expect slower tokens.
Don’t benchmark on first run. Caches warm up, downloads finish, and everything speeds up a bit after.
That’s it. You can be local-first by dinner and bragging about it by dessert.
Final Thoughts
Running LLMs locally isn’t about replacing GPT-4. That’s still out of reach for most of us.
It’s about ownership. My data stays with me, my costs are predictable, and I get to experiment however I want.
For me this setup has turned into a mix of practical tools and just plain fun. I’ve got a Jarvis-like assistant running in the background, a finance bot that can actually read my own files, monitoring agents that bug me on Discord, and on the laptop I can spin up Stable Diffusion for image generation whenever I feel like it.
It’s not perfect, but it’s mine. And that’s kind of the point.